// main.js [...] let workDir = __dirname+"/dbWorker.js";
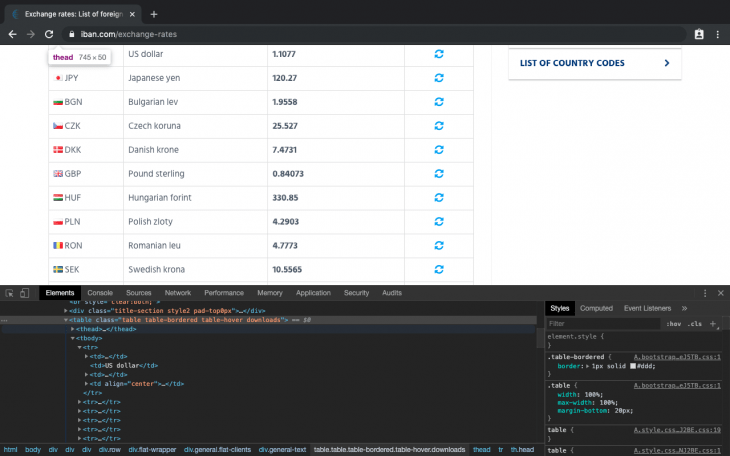
constmainFunc = async () => { const url = "https://www.iban.com/exchange-rates"; // fetch html data from iban website let res = awaitfetchData(url); if(!res.data){ console.log("Invalid data Obj"); return; } const html = res.data; let dataObj = newObject(); // mount html page to the root element const $ = cheerio.load(html);
let dataObj = newObject(); const statsTable = $('.table.table-bordered.table-hover.downloads > tbody > tr'); //loop through all table rows and get table data statsTable.each(function() { let title = $(this).find('td').text(); // get the text in all the td elements let newStr = title.split("\t"); // convert text (string) into an array newStr.shift(); // strip off empty array element at index 0 formatStr(newStr, dataObj); // format array string and store in an object });
return dataObj; }
mainFunc().then((res) => { // start worker const worker = newWorker(workDir); console.log("Sending crawled data to dbWorker..."); // send formatted data to worker thread worker.postMessage(res); // listen to message from worker thread worker.on("message", (message) => { console.log(message) }); });
[...]
functionformatStr(arr, dataObj){ // regex to match all the words before the first digit let regExp = /[^A-Z]*(^\D+)/ let newArr = arr[0].split(regExp); // split array element 0 using the regExp rule dataObj[newArr[1]] = newArr[2]; // store object }
// get current data in DD-MM-YYYY format let date = newDate(); let currDate = `${date.getFullYear()}-${date.getMonth()}-${date.getDate()}`;
// recieve crawled data from main thread parentPort.once("message", (content) => { console.log("Recieved data from mainWorker..."); fs.writeFile(path.join(__dirname, '../db/' + currDate + '.json'), JSON.stringify(content), 'utf8', function(err){ //如果err=null,表示文件使用成功,否则,表示希尔文件失败 if(err) { console.log('写文件出错了,错误是:' + err); } else { // send data back to main thread if operation was successful parentPort.postMessage("Data saved successfully"); } }) });