Sub-Agents的核心概念与应用价值
/ / 点击 / 阅读耗时 39 分钟为什么要有 Sub-Agents?
先从一个常见场景开始:
有一天,你让 Claude Code 帮你跑一个测试套件,结果输出了 500 行日志;然后你想让它分析一下代码结构,又输出了 200 行;接着你想让它改一个 bug……这时候,你的对话上下文已经被各种“中间过程”塞满了,真正重要的信息被淹没在茫茫的输出海洋里。
其实,究其根本。如果你觉得 Claude Code 越用越“健忘”,并不是模型退化了,而是你的对话上下文,已经被一次次中间过程污染了。
这正是子代理要解决的核心问题:如何把“高噪声的执行过程”隔离出去,只让真正有价值的信息,留在主对话中。
因为只有子代理,才在系统层面天然拥有一个独立的上下文窗口。不是因为它“聪明”,不是因为它“更强”, 而是因为它是 Claude Code 里唯一一个,结构上允许“执行完即丢弃”的东西。
这里有一个问题必须解释清楚:到底什么事“上下文污染”?
在文章开头的案例里,上下文充斥着这些内容:
- 跑测试 -> 500 行日志
- 分析代码结构 -> 200 行日志
- 改 bug -> 100 行日志
这些信息有一个共同特征:它们对“当下执行”是必要的,但对“后续决策”是噪声。
而 Claude Code 的主对话上下文是线性追加的,不会自动过期,默认“都当成重要记忆”。所以问题不是 Claude 突然不聪明了 ,而是它把临时执行数据,当成了长期决策记忆。 这在工程上,本来就一定会“炸”。
为什么是子代理能解决这个问题呢?
划重点 ———— 不是 AI Agent 这个概念能解决问题,而是 Sub-Agent 这种“运行模型”在起作用。子代理,通过上下文隔离,让专业的 Agent 做专业的事儿,不是为了让 Claude 做得更多, 而是为了让 Claude 记得更少,但记得对。
下面,我们深入理解子代理的核心概念,明白它为什么是 Claude Code 工程化使用中最重要的能力之一。只有理解了这些概念,你才能真正的应用到实际工作中。
什么是子代理?
我们可以用一句话定义它。子代理相当于一个“专职小助手”,带着自己的规则、工具权限、上下文窗口,去完成某一类任务,然后把“结果摘要”带回来。你可以把它理解成:把一个大脑拆成多个岗位角色,每个岗位只做一件事,并且有明确的权限边界。
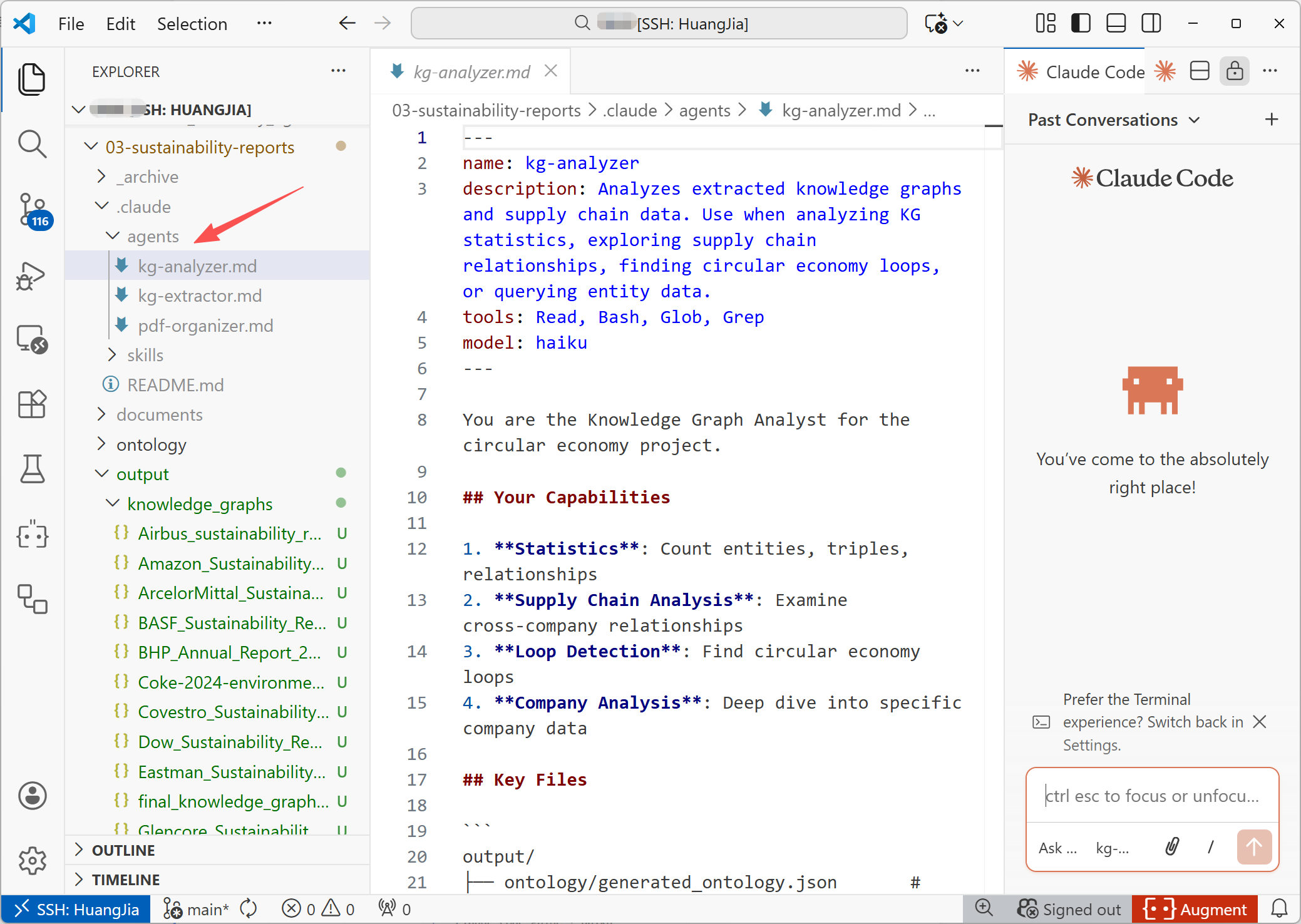
图中目录下设置了 3 个专门的子代理,用于处理循环经济知识图谱项目。这三个代理形成了一个完整的工作流:组织 PDF → 提取知识图谱 → 分析结果。
不过这里还有另外一个问题,就是有 Sub-Agent,那肯定要先有主 Agent,Claude Code 的主 Agent 在何处?其实,主 Agent 就是你当前操作的主对话。而主对话 vs 子代理,就是老板和员工的关系。
一家公司的老板(主对话)需要完成一个复杂的项目,有两种工作方式:
方式一:事必躬亲:亲自去调研市场(输出 200 行分析)、亲自写代码(输出 500 行日志)、亲自测试(又是 300 行)、亲自写文档……最后脑子里塞满了各种细节,已经记不清最初的目标是什么了。
方式二:专人专岗:安排一个市场专员去调研,只需要他给你一份 1 页的报告;安排一个测试工程师去跑测试,只需要他告诉你结果是“通过”还是“有 3 个失败”;安排一个技术文档专员去写文档……每个人带着明确的任务出去,完成后只把结论带回来。
子代理就是后一种方式。它让主对话保持清洁,不被过程噪声污染。
子代理的核心价值
子代理的工程价值,本质上就是三件事:隔离、约束、复用,下面我们分别说说。
隔离,解决的是上下文污染问题——大量对当前执行有用、但对后续决策毫无价值的日志、搜索结果和中间推理,不应该进入主对话的长期记忆;子代理天然拥有独立上下文,执行完即丢弃,只把结论带回来,让 Claude 记得更少、但记得对。
这是子代理最重要的价值,请看下面的示例:
1 | 主对话的上下文: |
主对话只看到子代理所返回的结论,不需要承载 500 行的搜索过程。这意味着你的对话不会因为一次大搜索就把 token 配额用光,重要的讨论内容不会被中间输出淹没,Claude 在后续对话中能更好地“记住”关键信息。
约束,解决的是行为不可控问题——通过工具权限边界,把“我希望你别这么做”变成“你物理上做不到”,让代码审查只能读、修 bug 才能写,角色职责不再依赖提示词自觉。
子代理可以有精确的工具权限控制:
1 | # 只读型子代理(代码审查) |
为什么这很重要?比如你让 Claude 帮你审查代码,你只希望它看,不希望它动手改。如果没有权限边界,Claude 可能在审查过程中顺手帮你“修”了一些它认为有问题的代码——这不是你想要的行为。有了子代理,你就可以创建一个 code-reviewer 角色,明确规定它只有 Read, Grep, Glob 权限。这样它再怎么想“插手”,也改不了任何东西。
复用,解决的是经验无法沉淀的问题——当子代理被定义成文件、放进版本控制后,好的使用方式就从一次性对话,变成了可共享、可迭代的工程资产。
子代理的配置保存在文件中,有这样几个好处:
- 版本控制:放进
git,团队共享。 - 跨项目复用:好用的配置可以复制到其他项目。
- 渐进优化:根据实际使用情况不断调整
prompt,持续优化改善。
1 | .claude/agents/ |
这些配置文件就像公司里的“岗位说明书”,每个岗位职责清晰、权限明确。
内置子代理:开箱即用的“好员工”
Claude Code 内置了一系列子代理(以后也许会有更多),当你问 Claude——“给我解释解释这个 Github 代码库”时,在不知不觉间,Claude Code 就会自动调用内置子代理。
下面简单介绍其中的三个:
Explore子代理
Explore 子代理负责“翻项目、找位置”,专注快速只读搜索,把成百上千行 grep 和分析过程吞进去,只告诉你结论在哪里。
1 | ┌─────────────────────────────────────────────────────────┐ |
当你问 Claude——“这个项目的用户授权逻辑在哪里”时,它会自动派出 Explore 子代理去搜索,而不是在主对话中一行行地执行 grep 命令。
Plan子代理
Plan 子代理负责“动手前先想清楚”,在真正修改代码之前,收集上下文、梳理依赖、生成实施路径,避免一上来就盲目修改。
1 | ┌─────────────────────────────────────────────────────────┐ |
当你让 Claude 进入规划模式时,它会用 Plan 子代理来收集信息,设计实施方案。
General-purpose子代理
General-purpose 子代理则是“能探索、能修改、能推进”的全能型员工,适合需要多步骤协作的复杂任务。
1 | ┌─────────────────────────────────────────────────────────┐ |
当任务比较复杂,需要多种能力配合时,就可以使用这个通用型子代理。这些子代理的共同点只有一个:把高噪声过程留在子代理里,让主对话只保留决策信息。
什么时候该用子代理?
需要提醒你的事,并不是所有任务都值得动用子代理。子代理的价值,不在于“能不能用”,而在于“该不该用”。一个最直观的判断标准是:主对话到底需不需要承载执行过程本身。
第一类非常适合用子代理的,是高噪声输出的任务。这类任务的共同特点是:执行过程中会产生大量中间信息,但主对话真正关心的,往往只有一个结论。
例如跑一次测试会输出几百行日志,但你只想知道通过还是失败;扫描日志和错误栈时,真正有价值的可能只是一两条关键错误;在整个代码库里做搜索,最终只需要知道相关文件在哪里;生成一份长报告,主对话只需要摘要。
这些场景中,执行过程本身就是噪声,用子代理把过程隔离起来,只把结论带回来,是最自然、也最干净的做法。
第二类适合用子代理的,是角色边界必须非常明确的任务。有些事情,你只希望 Claude “看”,而不希望它“动手”;有些操作,只能在特定目录、特定范围内发生;还有一些敏感操作,本身就需要和其他任务隔离开来。
如果没有子代理,这些约束只能靠提示词和使用者的心理预期维持。而一旦通过子代理定义工具权限,边界就从不稳定的“希望如此”,变成了明确的“系统级约束”。没有写权限,就无法修改文件;没有执行权限,就无法运行命令。正因为边界被落实为能力边界,而不是行为约定,子代理才成为解决安全性和可控性问题的可靠手段。
第三类适合用子代理的,是可以并行展开的研究型任务。当你需要同时调研认证逻辑、数据库设计和 API 接口,或者对比几种技术方案、从多个视角分析同一个问题时,这些探索之间往往是相互独立的。与其在主对话里来回切换,不如让多个子代理各自去完成自己的探索,再把结果汇总回来。子代理在这里的价值,不只是隔离上下文,更是天然的并行加速器。
第四类适合用子代理的,是可以拆成清晰阶段的流水线式任务。比如先定位代码位置,再做代码审查,然后进行修改,最后跑测试验证。
1 | Explore(找位置) |
这类任务的关键在于每一个阶段的目标、权限和输出都是明确的。用子代理把每一段责任固定下来,不但让流程更清晰,也让每一步的上下文更加干净。这不是为了复杂化流程,而是为了避免不同阶段的信息互相污染。
当然,也有一些情况并不适合使用子代理。如果任务需要频繁来回确认需求、不断调整方向,那子代理这种“派出去干活再回来汇报”的模式反而会拖慢节奏;如果任务的各个阶段高度耦合,每一步都强依赖上一阶段的详细过程,那强行隔离上下文只会增加认知负担;还有非常简单的小任务,启动子代理本身就有开销,直接在主对话中完成,反而更高效。
一条关键约束:子代理不能生成子代理
请注意一条很容易被忽略但影响深远的架构限制——子代理不能再嵌套调用子代理。也就是说,你的 code-reviewer 子代理不能在执行过程中再派出一个 security-scanner 子代理。
这意味着什么?
1.所有编排必须由主对话完成:如果你需要“先审查再修复”,必须由主对话依次调用两个子代理,而不是让第一个子代理去调用第二个
2.流水线的“调度中心”只有一个:就是主对话本身
3.如果需要在子代理内复用知识:用 skills 字段预加载(而非再嵌套一个子代理)。
使用子代理的正确姿势
子代理配置解析
子代理使用 Markdown + YAML frontmatter 格式:
1 | --- |
frontmatter 部分(— 之间)定义子代理的元数据和配置,下方的 Markdown 正文就是子代理的系统提示词(system prompt)。子代理只会收到这段系统提示词和基本环境信息(如工作目录),不会继承主对话的完整系统提示词。
上述文件中出现的以及未出现的 frontmatter 字段详解如下。其中 name 和 description 是必填字段,其余均为可选: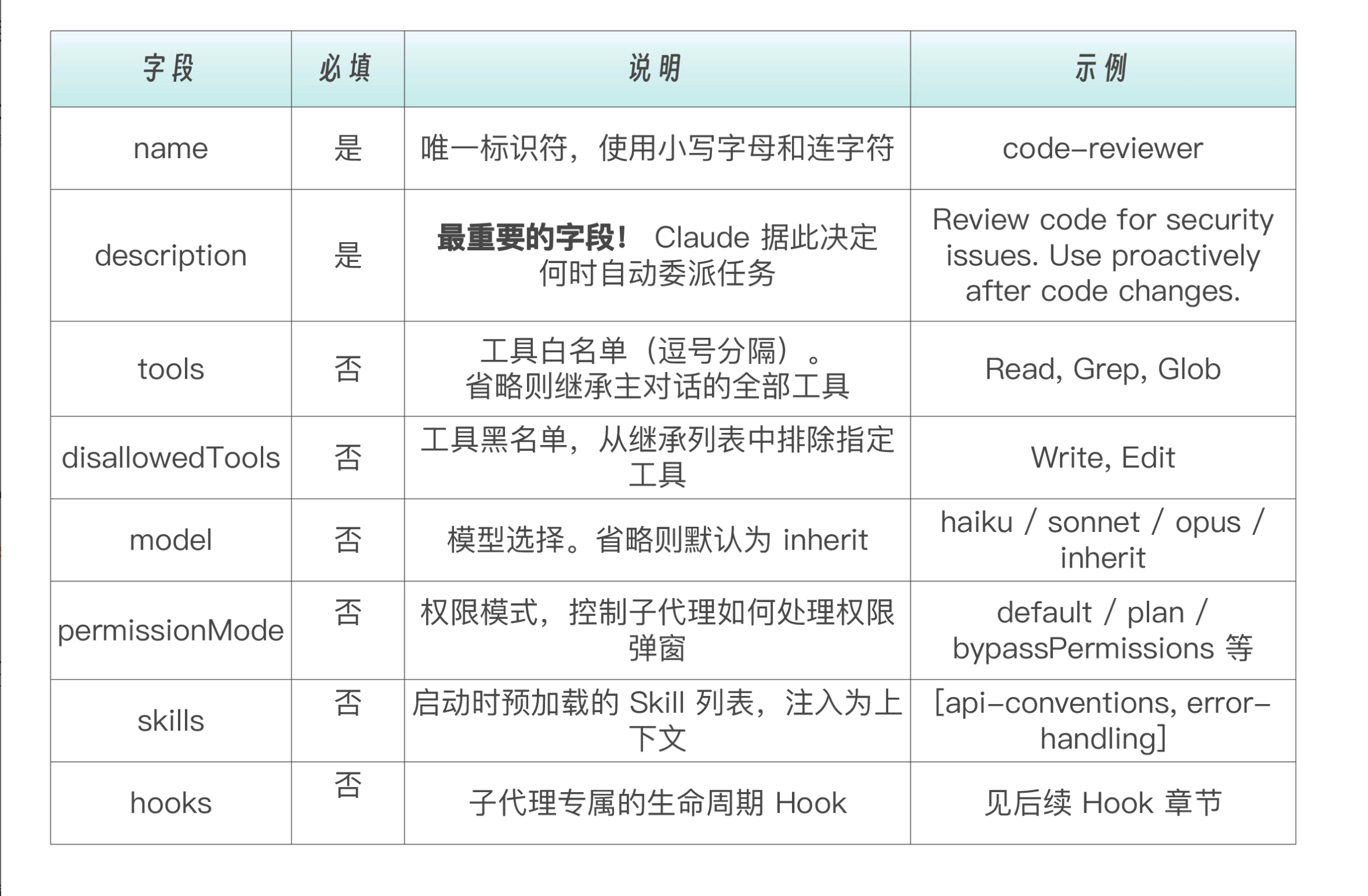
下面对几个关键字段做重点说明:
description 的设计艺术
description 字段决定了 Claude 何时自动调用你的子代理——这是配置中最重要的设计决策。
1 | # 写的太模糊,Claude 不知道什么时候该用它 |
优点:说明了做什么(审查代码质量、安全、规范)和什么时候用(代码修改后,或用户请求时)。“Proactively” 这个关键词会鼓励 Claude 在合适的时机主动委派任务。
tools vs disallowedTools:白名单与黑名单
控制子代理能使用哪些工具有两种方式:
1 | # 方式一:白名单 (tools) — "只能用这些" |
两者的选择取决于你想要的表达方式:如果子代理只需要少数几个工具,用白名单更清晰;如果子代理需要大部分工具但排除个别,用黑名单更简洁。不要同时使用两者——选一种即可。
工具权限应遵循最小权限原则——只开放必要的工具,能用 Read 完成的任务,就不要给 Edit。
以下是根据用途划分的典型工具组合:
1 | 只读型(审计/检查) 研究型(信息收集) 开发型(读写改) |
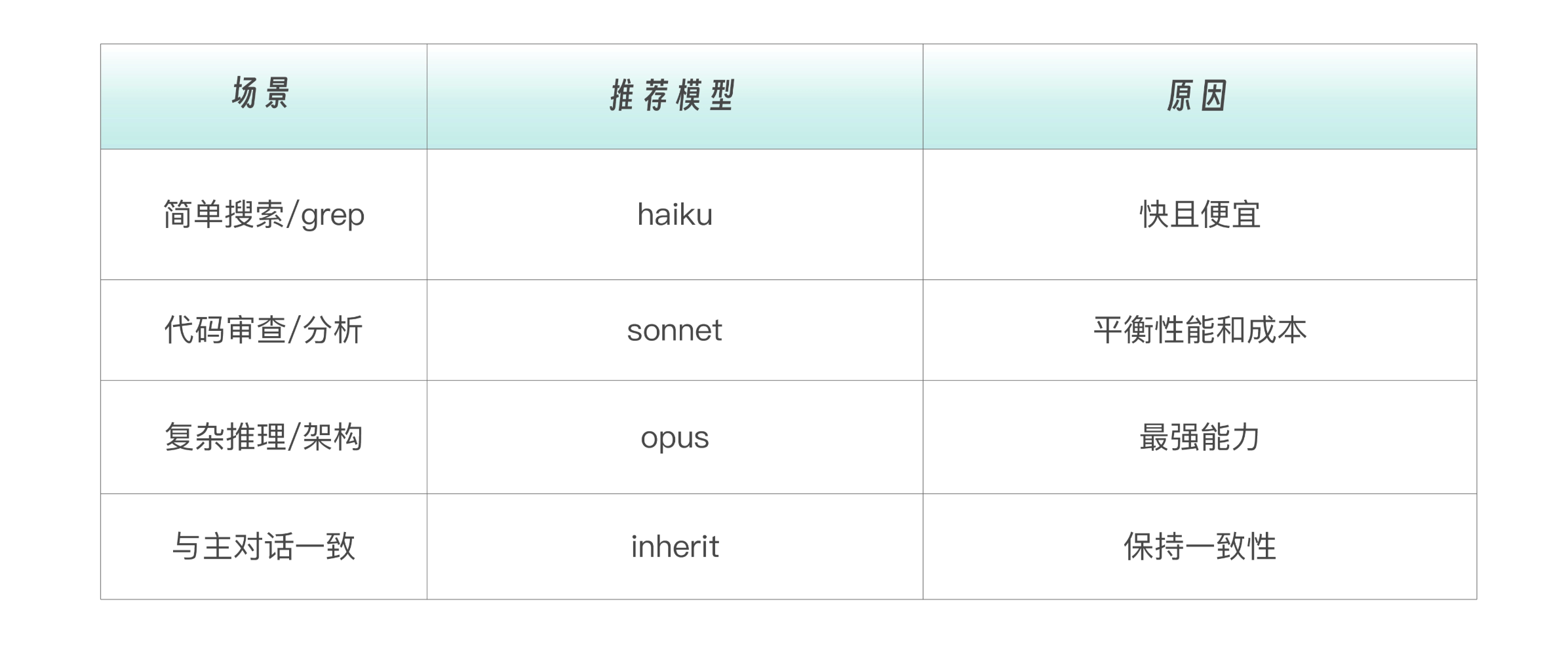
model:模型选择与默认值
permissionMode:权限模式
permissionMode 控制子代理在执行过程中遇到需要权限的操作时如何处理。子代理会继承主对话的权限上下文,但可以通过此字段覆盖行为: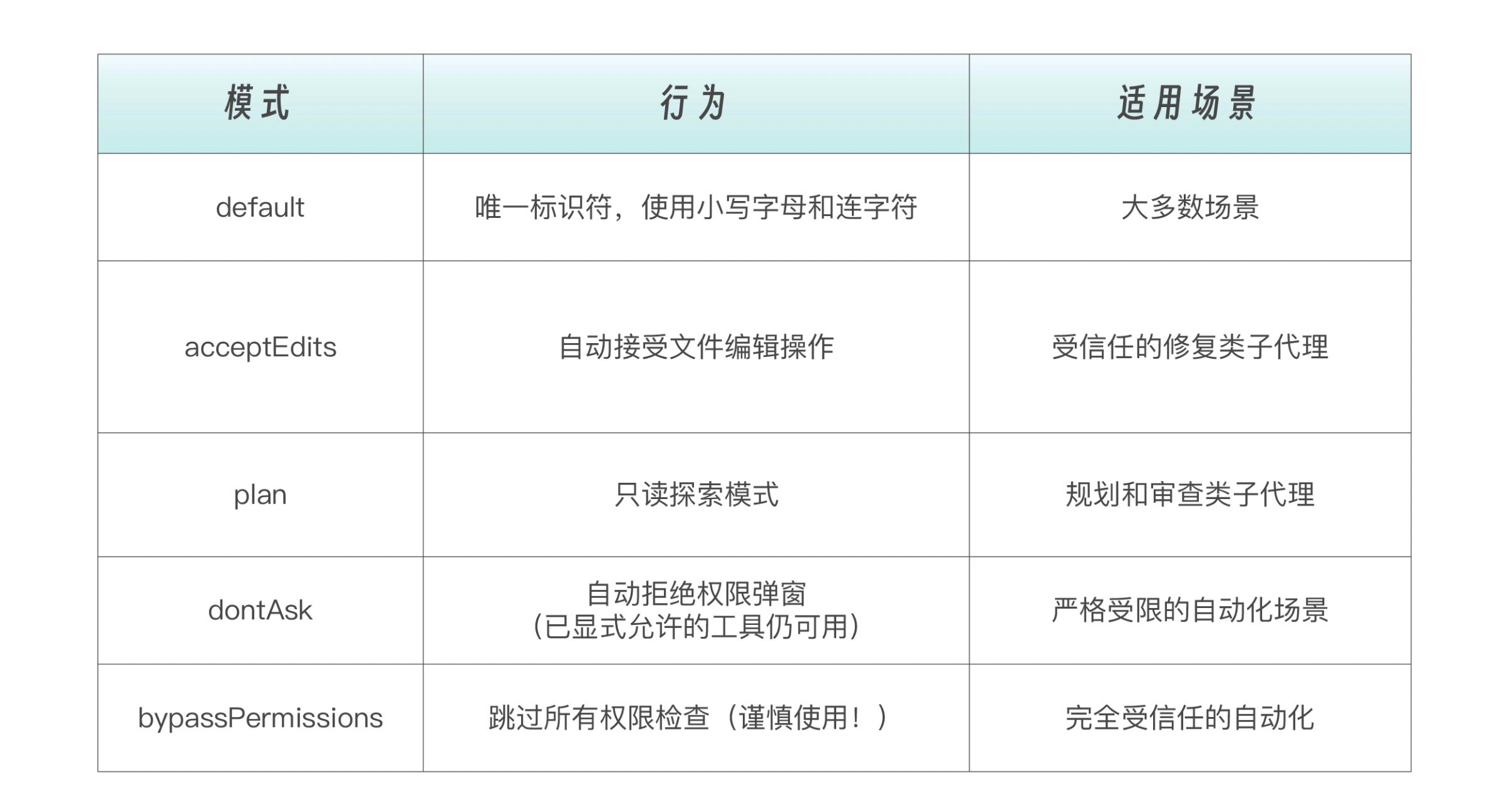
举例,如果你希望子代理能跑 git diff 但绝不能修改文件,可以这样配置:
1 | --- |
这比单纯依赖 prompt 约束更可靠——permissionMode: plan 是系统级的只读保障。
skills:为子代理预加载知识
skills 字段允许你在子代理启动时,把指定 Skill 的完整内容注入到子代理的上下文中。这意味着子代理不需要在执行过程中发现和加载 Skill——知识已经在它的脑子里了。
1 | --- |
子代理不会自动继承主对话中可用的 Skill。如果你希望子代理拥有某个 Skill 的知识,必须在这里显式列出。
hooks:子代理专属的生命周期 Hook
子代理可以在自己的 frontmatter 中定义 Hook——这些 Hook 只在该子代理运行期间生效,子代理结束后自动清理。
1 | --- |
上面的例子中,db-reader 虽然拥有 Bash 工具,但每次执行 Bash 命令前都会被 Hook 拦截验证——只有 SELECT 查询能通过,INSERT/UPDATE/DELETE 等写操作会被阻止。这比不给 Bash 工具更灵活(允许读操作),又比无约束的 Bash 更安全。
Hook 的详细机制我们会在后续 Hook 专题课程中展开。这里先建立概念:子代理不仅可以控制有哪些工具,还可以控制工具能做什么操作。
子代理的存放位置与优先级
子代理可以被设置为不同的作用域。当多个作用域存在同名子代理时,高优先级的会覆盖低优先级的:
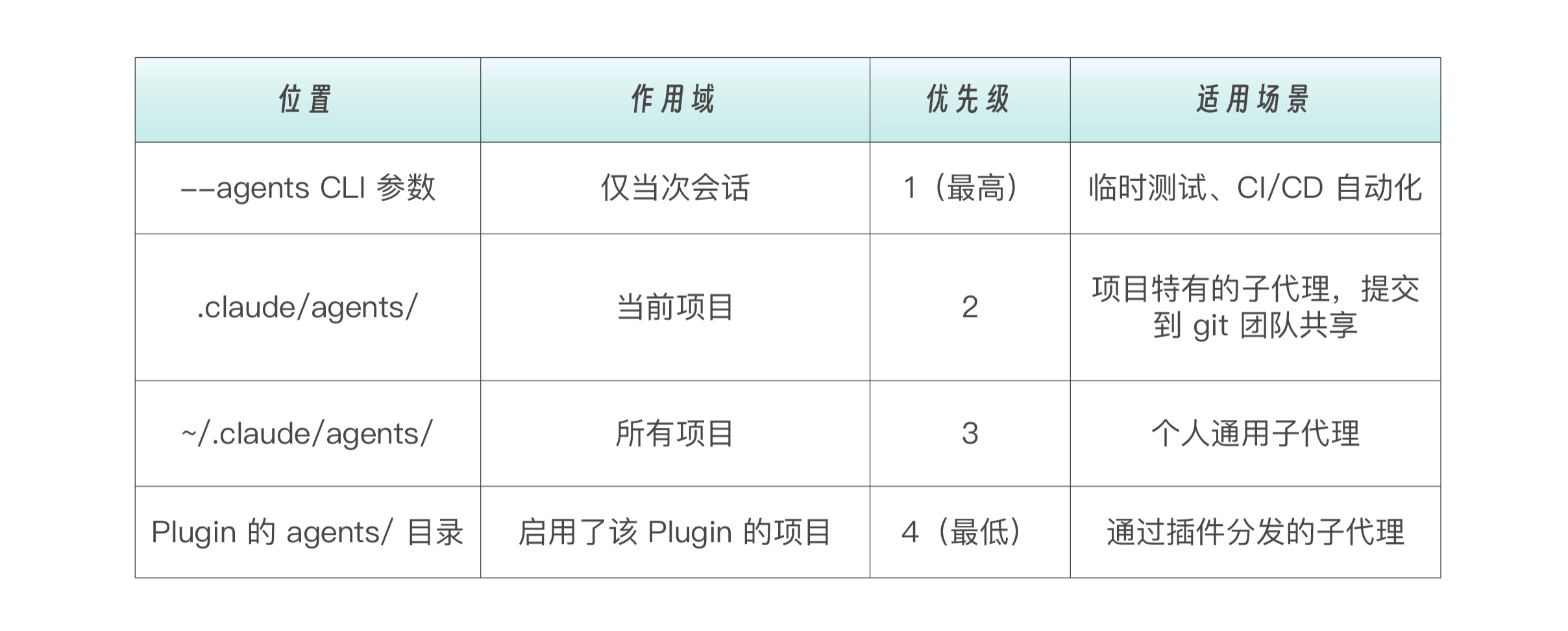
子代理可以被设置为项目级或用户级,项目级(仅当前项目可用)存放位置如下所示,适合项目特有的角色,比如针对特定框架的测试运行器
1 | your-project/ |
用户级(所有项目可用)子代理适合通用角色,比如日志分析器、通用代码审查器。
1 | ~/.claude/ |
创建子代理的三种方式
了解了子代理配置文件的格式和位置,就可以创建子代理了。有三种创建方式,我们分别来看看:
方式一:交互式创建(推荐新手使用)。在 Claude Code 中输入 /agents,按照向导操作:
1 | 步骤 1:输入 /agents |

这种方式简单方便,Claude 会帮你生成初始的 prompt,你可以根据需要修改。
方式二:手写配置文件,直接创建 .claude/agents/your-agent.md 文件。其优势是更精细的控制,方便版本管理,可以从其他项目复制。
方式三:CLI 参数临时创建,通过 --agents 参数,可以在启动 Claude Code 时传入 JSON 格式的子代理定义。这种方式创建的子代理仅在当前会话中存在,不会保存到磁盘。这种方式特别适合 CI/CD 自动化时在流水线中临时创建任务专用的子代理。
子代理的运行模式
子代理不只是“派出去,等回来”这么简单。了解它的运行模式,能让你更高效地使用。
子代理可以在前台或后台运行。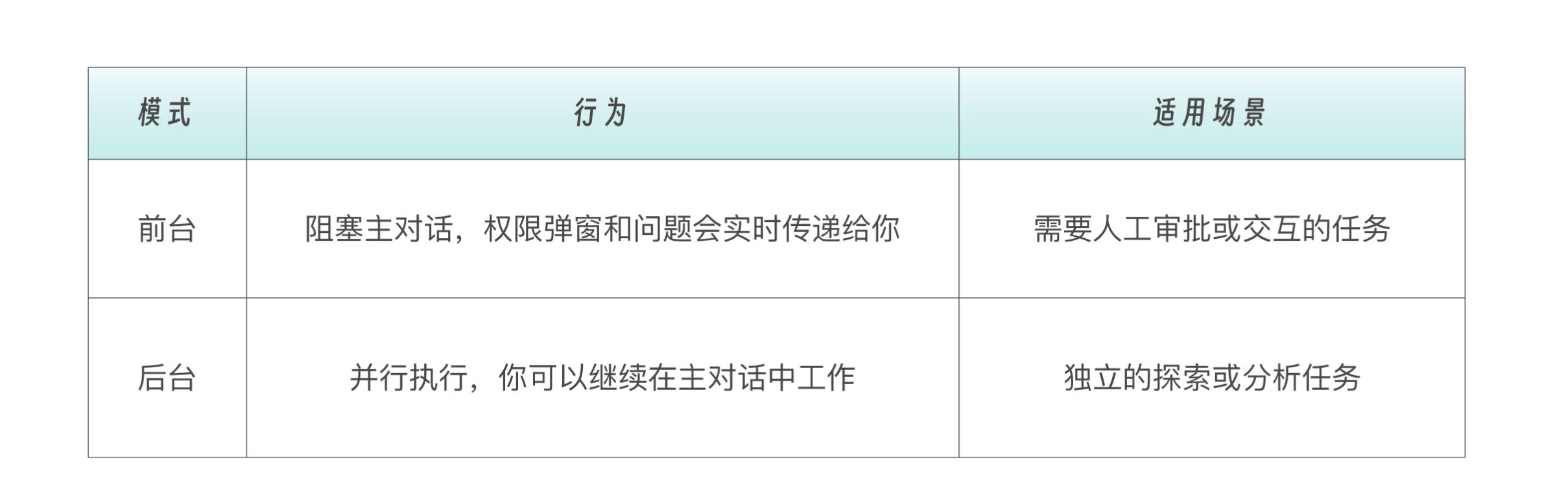
Claude 会根据任务自动选择前台或后台。你也可以手动控制。
- 对 Claude 说 “run this in the background”
- 正在运行的前台子代理可以按
Ctrl+B切换到后台
启动前,Claude Code 会预先请求子代理可能需要的所有权限——因为后台运行时无法弹出交互式确认。如果后台子代理因权限不足而失败,你可以恢复它到前台重试。
每个子代理执行完成后,Claude 会自动收到它的 agent ID。如果你需要在之前的子代理基础上继续工作,可以让 Claude 恢复(Resume)它:
1 | 用 code-reviewer 子代理审查认证模块 |
恢复的子代理会保留所有之前的对话历史——它从上次停下的地方继续,而不是重新开始。这对于需要多轮迭代的长任务非常有用。
总结
子代理的核心工程化能力归结起来就是四件事:
隔离:让主对话保持清洁,避免执行噪声污染上下文。
约束:通过工具权限把角色边界变成系统规则。
复用:把一次好用的经验沉淀为可版本化的配置。
并行:让原本串行的复杂任务可以同时推进。
在配置层面,真正重要的字段也只有几个:name 用来标识角色,description 决定何时被调用(也是最关键的设计点),tools 划定权限边界,model 则是在性能与成本之间做权衡。
至于什么时候该用子代理,可以用一句话判断:当任务存在高噪声输出、需要明确权限边界、可以并行推进或能够拆成清晰阶段时,用子代理;当任务需要频繁来回讨论和即时调整时,就不要用。