SKILL.md结构与触发机制
/ / 点击 / 阅读耗时 25 分钟从第一性原理来解释什么是 Skills
在真实的工程团队里,很少有人能够把所有规范背下来。
代码风格指南十几页,Git 提交规范三四种类型,API 设计有版本约定,安全审查有检查清单,部署流程有风险控制条款……这些规则并不复杂,但数量一多,就不可能长期驻留在脑中。人类工程师的做法很简单:需要时再查阅。
如果我们把 Claude 当作真正的工程助手,它也会面临同样的问题。最直接的做法,是把所有团队规范写进 CLAUDE.md,让模型每次对话都读取这些内容。短期看这是可行的。但当知识规模扩大到几十页甚至上百页时,问题就出现了——每一次对话都在为“可能用不到的知识”支付上下文成本。这不仅消耗 tokens,更重要的是,它会稀释模型的注意力。真正需要用到的规则,反而淹没在冗余信息里。
这正是 Skills 出现的背景。
Skills 并不是简单的“能力扩展机制”,它本质上是一种按需加载的认知结构。与其把所有知识常驻在上下文中,不如把它们封装成可独立触发的能力单元。当模型判断当前任务涉及某个特定领域时,再加载对应的知识与操作流程。
因此,我们可以给 Skills 一个更精确的定义:Skills 是一种可被语义触发的能力包,它包含领域知识、执行步骤、输出规范与约束条件,并在需要时渐进式加载到主 Agent 的认知空间中。
如果我们把 Agent 生态整体展开来看,会发现 Skills 并不是孤立存在的。Agent 生态中有四大支柱,每个都解决了一个根本性问题:
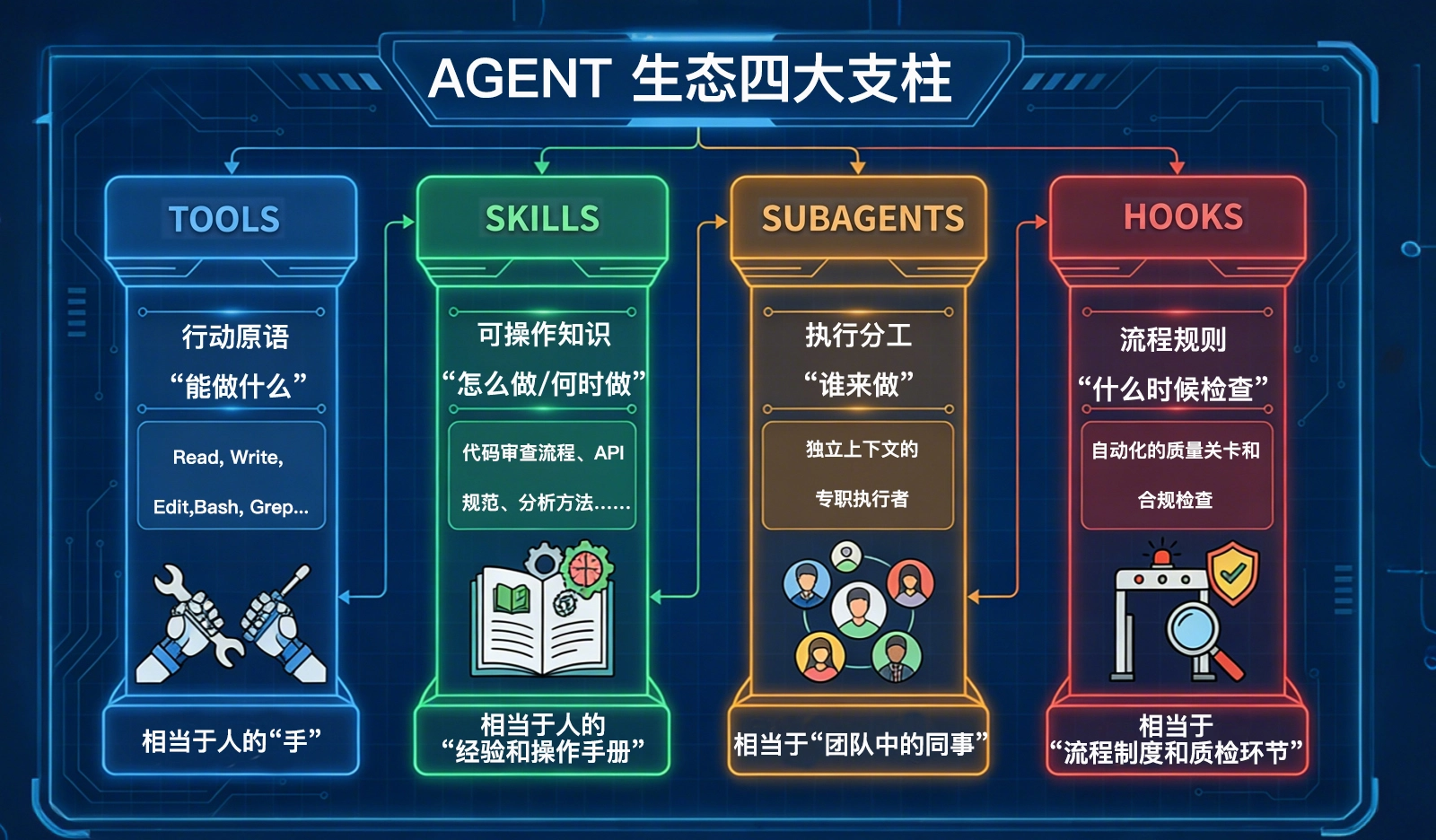
Tools 是行动原语。它回答的是能做什么。读文件、改代码、执行 Bash 命令……这些是操作层面的能力,类似人的双手。
SubAgents 是执行分工。它回答的是谁来做。当任务复杂到需要独立上下文时,子代理承担专职职责,类似团队中的同事。
Hooks 是流程规则。它回答的是什么时候检查。它们在关键节点自动触发质量校验或合规约束,类似企业中的质检流程。
而
Skills回答的,是另外一个非常关键的问题:“怎么做,以及何时做”,它不是工具,也不是分工机制。它是一种可操作知识结构。
Skills 解决的核心问题是,在有限的上下文窗口中,让 Agent 在正确的时刻拥有正确的领域知识。
这不是工具问题(Tools 回答“能做什么”),也不是分工问题(SubAgents 回答“谁来做”),而是认知问题——Agent 需要知道特定领域的规范、流程、模式,才能做出正确决策。
Skills 的核心生态位——可操作知识
很多人会把 Skills 理解成“结构化文档”,但可操作知识与被动文档之间,存在本质区别。
一份 API 设计指南放在 Wiki 上,是静态文本。它不包含触发条件,不定义执行流程,不规定输出结构,也不会自动校验质量。它等待人去阅读。
而一个 Skill,则是一段具备语义入口的标准操作程序。它通过 description 告诉模型:在什么情况下应该加载这项能力。它在正文中定义执行步骤,将抽象原则转化为可执行流程。它通过模板约束输出格式,确保结果标准化。它可以限制可调用工具的范围,防止越权操作。它甚至可以通过 hooks 在完成后自动执行验证逻辑。
当我们把文档封装为 Skill,它就不再是参考资料,而成为一种可被调用的行为模式。从工程视角看,这是对上下文资源的优化;但从系统设计视角看,这是一种更深层的变化。
过去的软件体系中,调度权始终掌握在人类手中。工程师写 Prompt、编排 Workflow、定义调用顺序。模型只是执行者。路径在设计时就被固定下来。但当知识规模持续扩大、场景组合持续增长时,这种“人预编排一切”的模式开始失效。我们无法穷举所有路径,也无法为每一种场景写出完整流程。
Skills 的真正突破点,在于它把能力的“语义定义权”交给模型。
人不再编排具体执行路径,而是定义能力的边界与含义。模型根据 description 理解能力语义,并在运行时决定是否加载、何时加载。这看似只是增加了一个字段,却完成了一次范式跃迁。我们从“人调度模型”,走向“模型调度能力”。
正因为“模型调度能力”和“可操作知识”的重要性,Skills 已经逐渐脱离了 Claude 的语境,成了 Agent 生态中的通用概念。“技能化”思路正在从 Claude 系统扩展到其他智能体平台,以及 AI 赋能的工程工具中。
企业本体论视角:Skills 是组织的 SOP 体系
当这种“可操作知识”机制扩展到企业层面,它的意义会更加清晰。
如果把 Claude Code 的技术栈映射到企业组织结构,我们会发现一种高度对称的关系。Tools 对应员工的操作工具;SubAgents 对应岗位分工;Hooks 对应质量与合规流程;CLAUDE.md 类似企业文化与通用规章;MCP Servers 像外部合作伙伴;Plugins 是对外打包的解决方案。
而 Skills,正是企业的 SOP 体系。
一个成熟的企业不会要求员工背诵全部操作手册。相反,它建立标准操作程序,在具体任务发生时按需查阅,并按照步骤执行,输出标准化结果。当新员工进行代码审查时,他不会即兴发挥。他会参考《代码审查 SOP》,按步骤检查,最后输出符合模板的报告。
Claude 在加载 code-review Skill 时,所做的事情,本质上是同一个过程。从这个角度看,Skills 不再只是技术机制,而是一种企业经验的结构化表达方式。
当组织的“做事方式”被封装为可语义调用的能力单元,经验就不再依附于老员工的记忆,也不再散落在文档系统中。它变成模型可以理解、选择和继承的结构。
对于企业来说,把专业流程、领域知识和行动判断封装成可复用的能力单元,然后让智能体按需加载和调用,这是一种让通用模型具备专业化、按需调用能力的通用设计模式。类似 Skills 的模块化能力已经被用于数据分析、校验、报告生成等任务,把自然语言指令转化成结构化的专业工作流;也有技术方案将企业组件库、开发规范等封装成“技能包”,让模型自动发现、理解并正确应用这些业务能力。
为什么Skills 会在这一轮 Agent 浪潮里真正出圈?并不是因为它多好用,而是因为它第一次把长期被忽略的问题,放到了系统层面来解决 ———— 谁来判断 “什么时候应该用什么能力”
Skills的突破点在于:它不再要求人预先编排所有路径,而是把“能力的语义定义”放到了模型中。模型根据 description 理解能力语义,并在运行时决定是否加载、何时加载。这看似只是增加了一个字段,却完成了一次范式跃迁。我们从“人调度模型”,走向“模型调度能力”。
深入了解 Skill 触发机制
在 Claude Code 中,Skills 默认情况下支持两种触发方式:
- 用户显式触发: 输入/skill-name,例如:/review src/auth.ts
- 分层审批:Claude 读取 description,语义匹配后自动加载,例如用户说“帮我审查这段代码”,Claude 激活 code-review Skill 进行审查。
和 Sub-Agents 类似,Skills 的触发机制靠 LLM 语义推理,而非精确匹配。Claude 读取所有 Skills 的 description,通过语义理解判断当前对话是否匹配某个 Skill。
当用户发送消息时,Claude 的处理流程如下图所示:
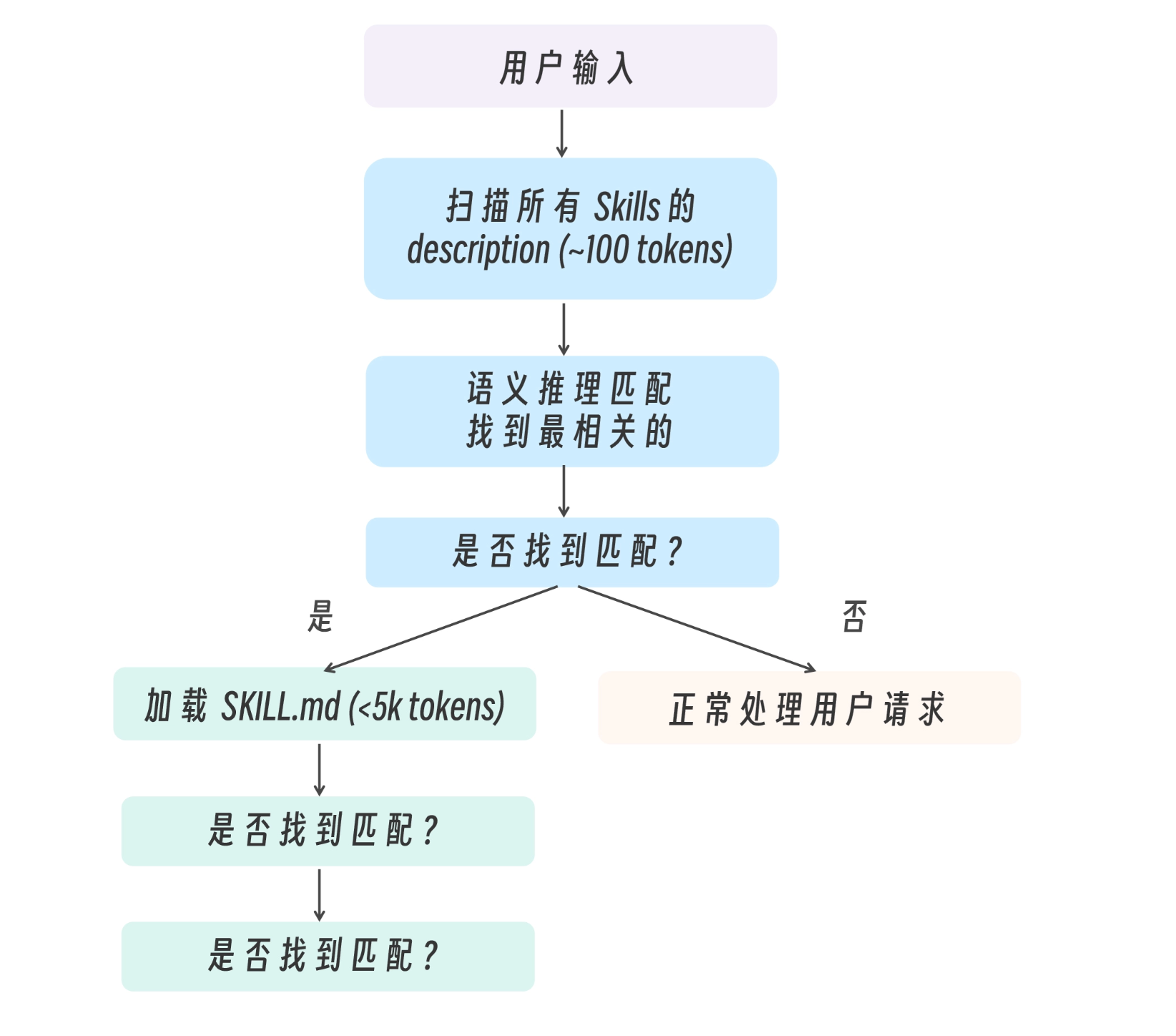
当用户请求可能匹配多个 Skills 时,Claude 会:
- 评估每个 Skill 的 description 与用户请求的相关性。
- 选择最相关的那个。
- 如果不确定,可能会询问用户或使用通用方式处理。
两大类型的Skills:参考型和任务型
从工程角度,Skill 内容分为两类,参考型和任务型。参考型 Skill 影响“怎么做”,任务型 Skill 决定“做什么”。前者是语义环境,后者是具体行动。
你在写 description 时需要明确它属于哪种类型:
1 | # 参考型——Claude 自动选择是否使用 |
创建一个参考型 Skill
在 Claude Code 中,每个 Skill 独占一个目录,其标准的目录和文件结构如下:
1 | .claude/skills/<skill-name>/SKILL.md |
我们即将要创建的这个参考型 Skill 是一个“API 设计规范”:
1 | .claude/skills/api-conventions/ # skill 目录,名称即 skill 名 |
这个文件有三个部分:
- YAML frontmatter,是通过—包裹的元数据
- Markdown 正文,是技能的具体说明
- 辅助文件:.claude/skills//SKILL.md——每个 Skill 在自己的目录中,可以包含辅助文件(此处只有主文件,下一讲中的示例我们将看到辅助文件)。
注意这个 Skill 的关键特征——它是一个典型的参考型 Skill:
- 没有执行步骤:不是先做A再做B,而是“遵循这些规范”。
- 没有输出模版:不要求 Claude 输出固定格式的报告。
- 没有设disable-model-invocation:Claude可以自动判断何时需要。
- 只读工具:allowed-tools 限制为 Read/Grep/Glob,因为不需要修改代码。
description 是 Skill 的灵魂,因为它不是给人看的文档,而是给 Claude 看的触发器。Claude 选择是否激活一个 Skill,完全依赖于阅读 description。这不是关键词匹配,而是语义理解。
1 | 用户输入: "帮我看看这段代码有没有问题" |
如果你这样写 description,想想看合适么?
1 | description: Handles PDFs |
很明显,问题在于太模糊,“handles”是什么意思?读取?转换?合并?Claude 不知道什么时候该用它。用户说“帮我处理这个 PDF”时,Claude 可能不确定这个 Skill 是否合适。
我们再对比一下更好的 description 长什么样:
1 | description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction. |
为什么这版更好?因为它列出了具体动作(extract, fill, merge);包含了用户可能说的关键词(PDF, forms, document extraction);明确说明了触发场景(“Use when…”)
总结一个 description 写作公式:
1 | description: <做什么> + <怎么做> + <什么时候用> |
套用公式创作的几个Skill:
1 | # 代码审查 Skill |
总结
- Skills 是由用户或 Claude 触发的能力包,Claude 通过语义推理决定何时激活,但目前已经脱离了 Claude Code 本身,形成了 Agent 通用技能生态。
- Skill 的 description 不是文档,而是触发器,其构建公式为:做什么 + 怎么做 + 什么时候用
- Claude Code 采用渐进式加载来节省token,description常驻上下文,全文仅在触发时加载。
当我们谈论 Agent 系统的工程化时,我们真正面对的问题,并不是“模型是否足够强大”,而是“模型在何时拥有何种知识”。Skills 给出的答案,是通过语义定义与按需加载,让能力在正确的时刻出现。在有限的上下文窗口里,组织的做事方式第一次获得了结构化存在的形式。